
爬虫的使用(python)
案例一 获取王者荣耀英雄数据
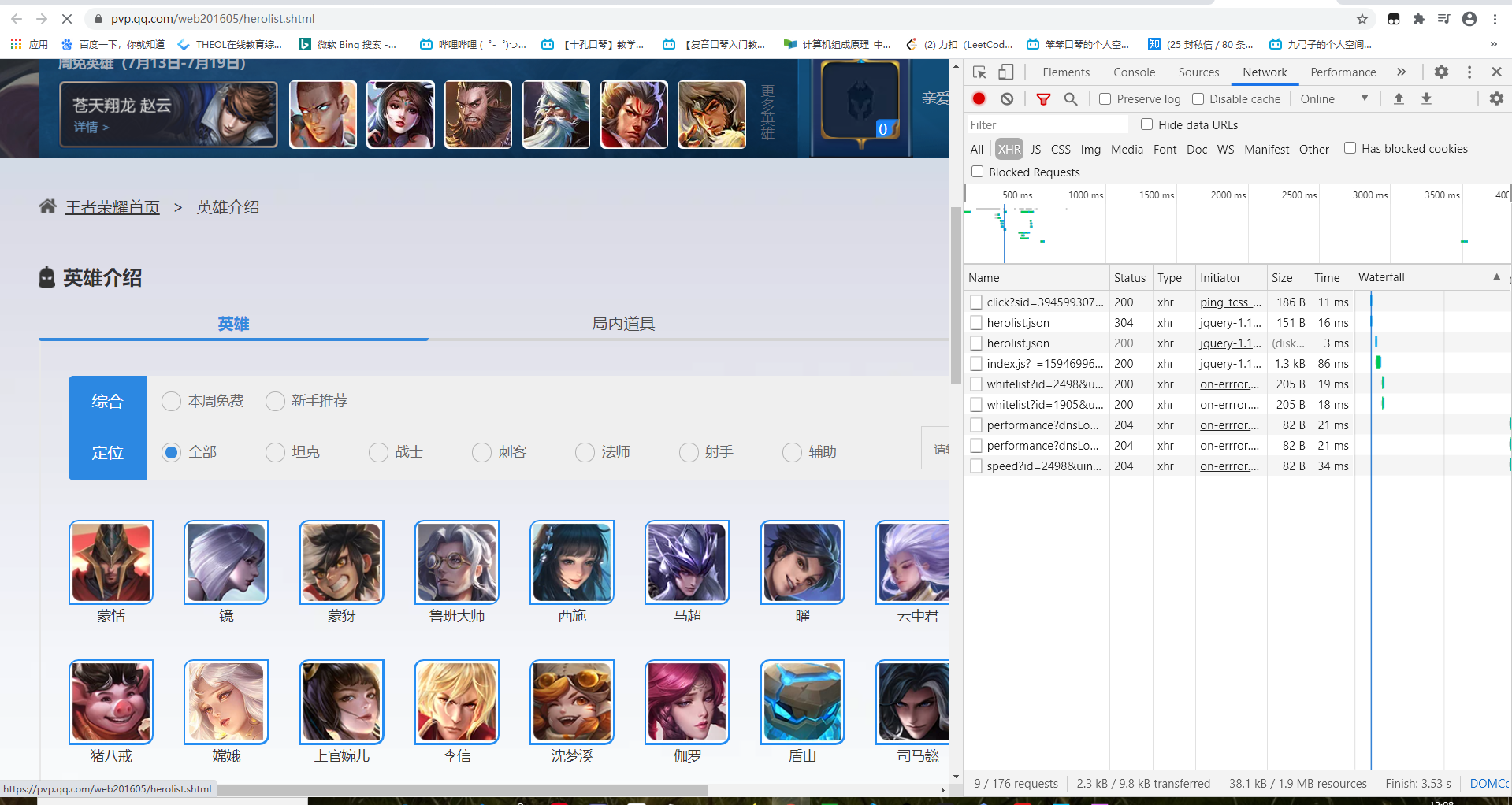
- 发现英雄列表的请求数据
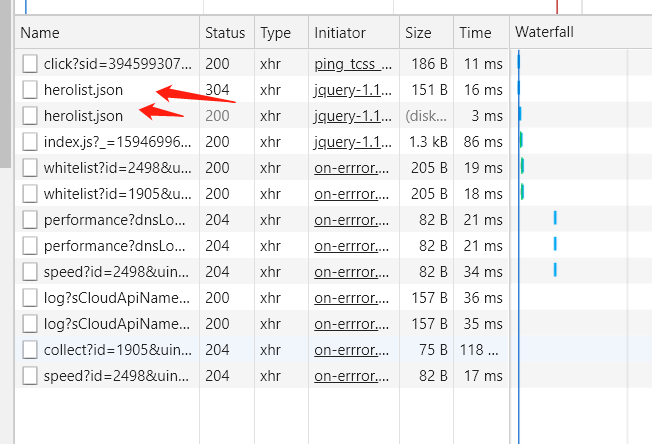
- 然后随便打开一个英雄的介绍网页,鼠标右键查看源代码分析标签内容,方便后面进行爬虫获取

打开vscode,写python代码,前提安装好并配置好python环境,我已经安装配置完成

然后要安装这两个库(复制到命令行安装就行)
1 | pip install requests |
- 如何获取(总纲)要模拟发出网络请求
1 | import requests |
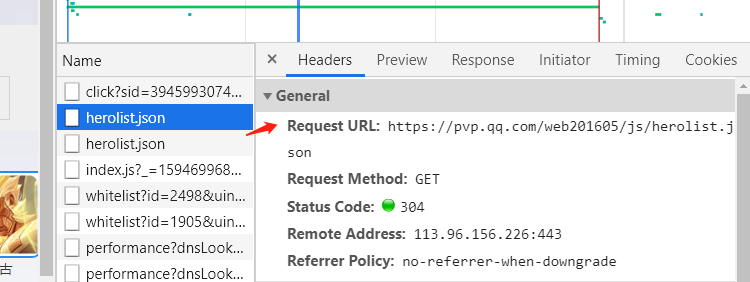
- 点击herolist,查看请求头地址网址
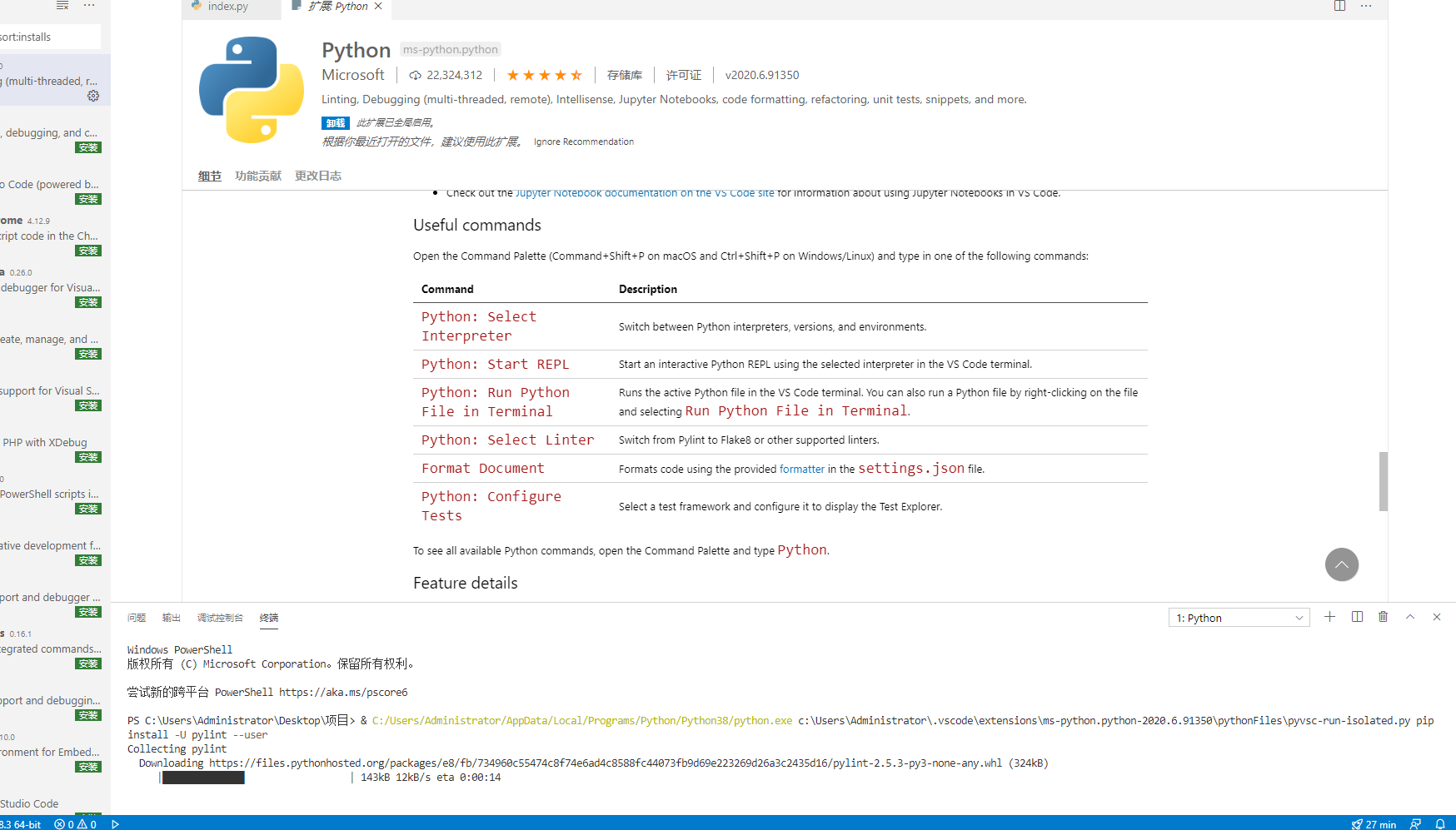
如果要在vscode运行python程序要安装这个插件
1 | import requests |
点击运行到终端,发现有输出

后面就写数据库代码
下载mysql
参考文档写增删改查即可(不同数据库略有不同)
我本机没有安装,就没有演示
总结
1.模拟请求获取数据(安装依赖)
2.处理数据(循环)
3.插入到数据库(insert)
